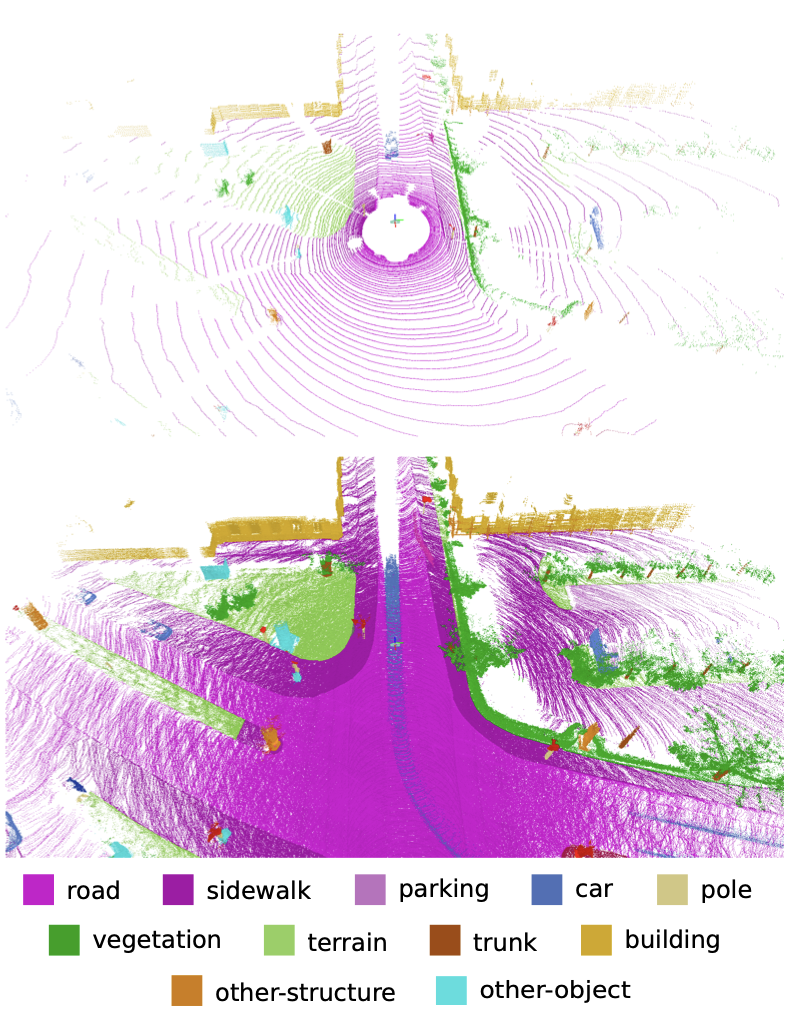
SemanticKITTI is a large-scale dataset of over 43,000 LiDAR scans, obtained by annotating all 22 sequences of the KITTI Vision Odometry Benchmark with dense point-wise semantic labels for the complete 360-degree field-of-view of the rotating automotive LiDAR sensor.
This dataset is intended for research in laser-based semantic segmentation and semantic scene completion.
@inproceedings{behley2019iccv,
author = {J. Behley and M. Garbade and A. Milioto and J. Quenzel and S. Behnke and C. Stachniss and J. Gall},
title = {SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences},
booktitle = {Proc. of the IEEE/CVF International Conf.~on Computer Vision (ICCV)},
year = {2019}
}




