RoboSet is a large-scale dataset collected on a range of everyday household tabletop multi-task activities. Each instance of the dataset is a robot trajectory, capturing essential information at each time step, including: observations, actions, rewards, RGB images from multiple camera views, and other relevant environmental information.
RoboSet contains a mix of kinesthetic demonstrations and teleoperated demonstrations, in both simulation and in the real world. There are also two types of trajectory collection: human teleoperation (using Puppet) and expert trajectories (rollouts from a trained NPG policy for the target task).
RoboSet is intended to support pre-training, visual and policy learning generalization, and offline robot learning, like imitation learning and offline reinforcement learning.

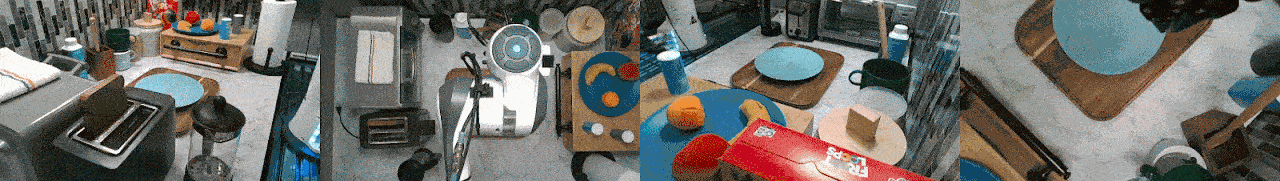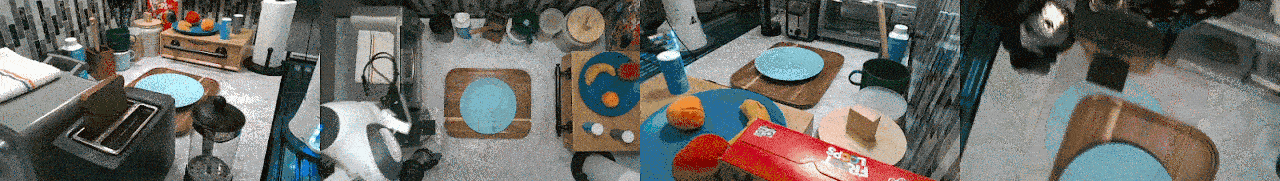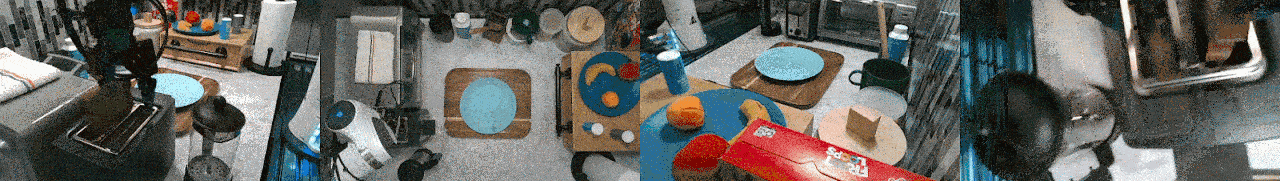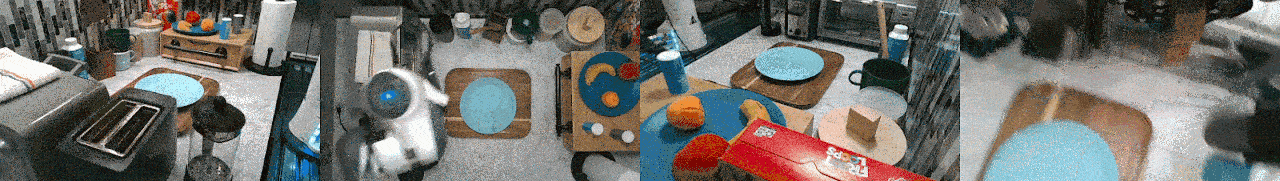
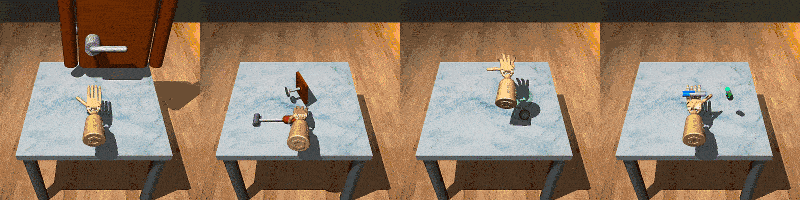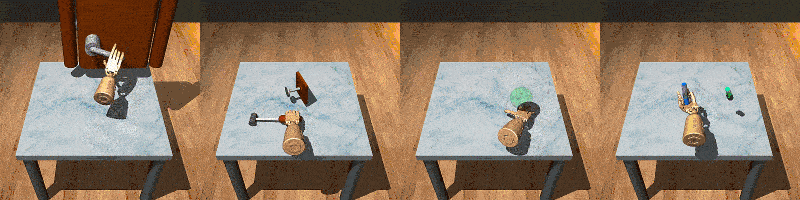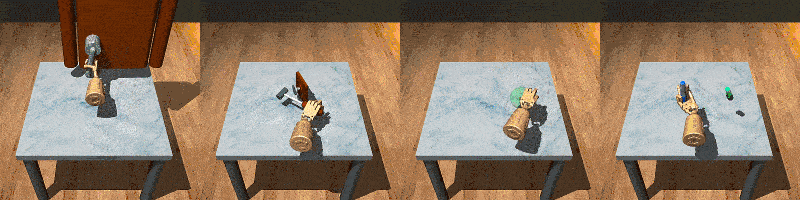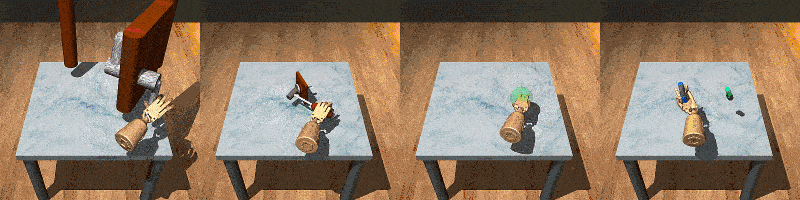
@inproceedings{RoboHive,
title = {RoboHive -- A Unified Framework for Robot Learning},
author = {Vikash Kumar, Rutav Shah, Gaoyue Zhou, Vincent Moens, Vittorio Caggiano, Jay Vakil, Abhishek Gupta, Aravind Rajeswaran},
booktitle = {NeurIPS: Conference on Neural Information Processing Systems},
year = {2023},
url = {https://sites.google.com/view/robohive},
eprint = {https://arxiv.org/abs/2310.06828}
}




